1 设计规范
1.1 必须使用分布式主键
解读:
l 分库分表后使用依旧使用自增主键会导致后续分库分表扩容时主键全部需要重写,并且其他数据依赖方(如大数据)取数聚合计算时出现冲突
l 主键就是对数据的唯一标识键,哪怕分库分表了也应该是如此
1.2 分库分表前需要谨慎评估是否真的需要分库分表
解读:
l 分库分表会带来更多的问题,不带分表键的查询都不支持,对业务的限制更多
l 根据业务特性,可以采用不同的分库分表方式或者不分表,如使用日期分表或者定期迁移历史数据
l 现在硬件性能上去了,单表一两千万的性能完全是OK的
1.3 分库分表的分库分表数需要互质
解读:
l 例如共分m个库n个表,m与n需要互质,即mn之间必须没有公约数,否则会导致部分库部分表永远没有数据,数据严重倾斜
l 因为逻辑都是根据分表键去mod,若分表键值为k,举一个例子,m=4,b=256时,在第0个库的第18张表将永远没有数据,因为k%4=0 && k%256=18,这个k在实数域不存在
l 网上的证明:

1.4 选择分表键时,要考虑数据的倾斜
解读:
l 这是很基本的规范,没有人会拿性别当分表键去分表
l 大部分场景的分表,第一次分表都是使用userId的
2 使用规范
2.1 禁止任何对分库分表的查询不带分表键
解读:
l 好像没什么好解读的,不带分库分表键的查询就会全部分库分表全表扫描,应用内存io和数据库内存io直接炸了
2.2 禁止使用联合查询join
解读:
l 尤其是分库后,要join的数据不一定在一个库,最后还是在应用内存里做了
2.3 使用分表键查询时,禁止使用分表键in()
解读:
l 我们用的sharding版本4.1.1,哪怕是使用in查询分表键,也不会先根据分表键路由来决定要查询哪些表,而是每张表去in一次
l 即使高版本有优化,那随着in()语句里数据量的变大,对不同库表的io也会增多
2.4 查询时,需要指定字段,而不是使用表名.*或者select *
解读:
l 这个.*的方式,在ddl增加字段后,sharding是无法感知并更新metadata的,会导致返回的字段混乱,并且sharding版本不同出现的错还不太相同,主要会有:直接报错,丢失字段,后面字段被覆盖这些问题
https://github.com/apache/shardingsphere/issues/23475
https://github.com/apache/shardingsphere/issues/22824
2.5 禁止不带分表键的limit order等操作
解读:
l sharding在执行不带分表键查询的limit或order等操作时,为了获取正确的数据,会把sql进行转化,如limit 100,10,会转化为对每个表执行limit0,100并在内存里聚合数据,这样在limit的第一个值过大时,会转化成对所有表进行全表扫描全部数据拉取
总结:
l 对于分库分表后的业务表,只使用单分表键+其他查询条件的查询,并且不能使用join
l 编写相关sql时,一定要脑袋里过一下,这个sql在分库分表的逻辑上是否能定位到分库分表的某张表上执行,如果不能,那么这个sql一定会导致应用层或者代理层去进行聚合操作,这种sql一定要禁止
3 常见问题解决方案
这也不能那也不能,那么很多问题怎么解决?
3.1 如果需要非分表键的查询
方案:
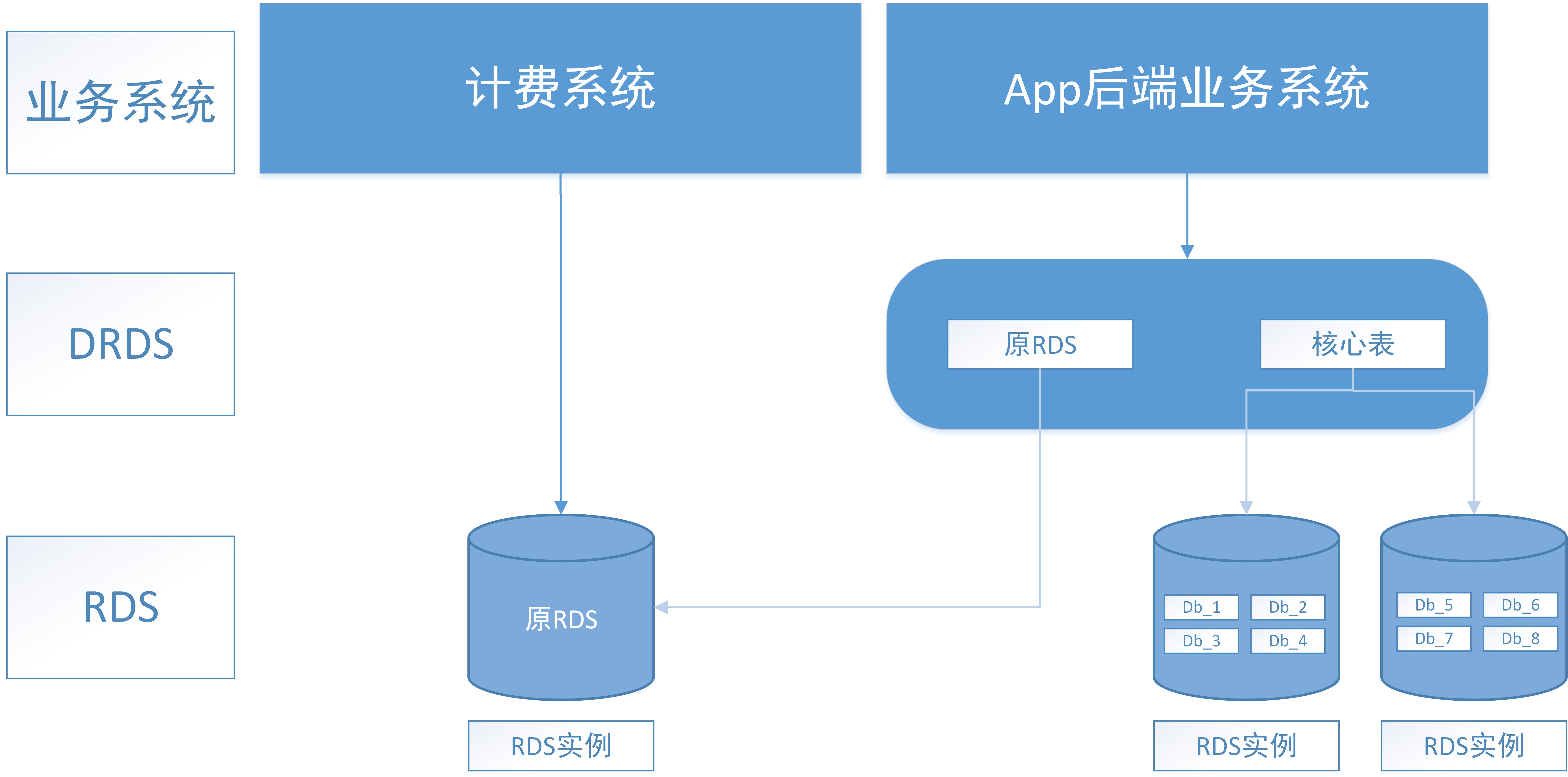
l 使用影子表,并且通过双写或者binlog来同步数据(视延迟要求而定),影子表即和分表结构一样,但是分表键不同的表
l 交给大数据来