本文最后更新于 714 天前,如有失效请评论区留言。
SRE是什么
SRE(Site Reliability Engineering)即网站可靠性工程,以软件工程的方法论重新定义研发运维,驱动并赋能业务演进。
SRE的职责
SRE主要负责所有核心业务系统的可用性、性能、容量相关的事情,根据《Site Reliability Engineering 》一书提及的内容,笔者做简单汇总,SRE的工作主要包括但不限于如下:
-
基础设施容量规划
-
生产系统的监控
-
生产系统的负载均衡
-
发布与变更工程管理
-
on-call(轮值) 与 Firefighting(紧急故障救火)
-
与业务团队协作,共同完成疑难问题的处理
要做哪些事情
-
基础组件能力提升
-
性能优化
-
数据库稳定性治理
-
监控预警治理
-
故障诊断与恢复
-
变更流程规范
-
on-call轮值
-
稳定性日报
这些事情怎么做
### 基础组件能力提升
-
AHAS能力接入
-
整体上云
性能优化
-
数据库慢sql优化
-
慢接口优化
-
rediskey优化
### 数据库稳定性治理
- 主从库读写分离
### 监控预警治理
-
arms监控
-
error日志监控
-
云中间件监控
-
监控配置
### 故障诊断与恢复
-
全链路日志串联
-
rds的sql分析
-
Prometheus监控指标
-
redis缓存分析
-
故障复盘
### 变更流程规范
-
线上变更钉钉群通知
-
dms多级审批
-
变更评审以及发布评审
### on-call轮值
-
高峰期项目稳定性全天9:00-21:00点轮班
-
SRE小组全天8:00-20:00轮班
稳定性日报
- 高峰期稳定性日报
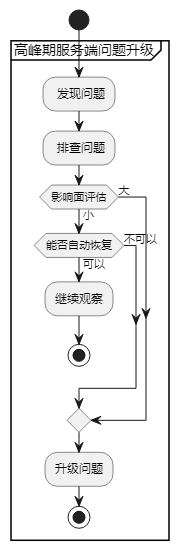
异常怎么处理
-
拉通相关人员,及时同步信息
-
确认故障范围,减小故障规模
-
编写故障手册,规范处理步骤
-
参照异常处理手册