服务端应急处理流程
问题升级流程
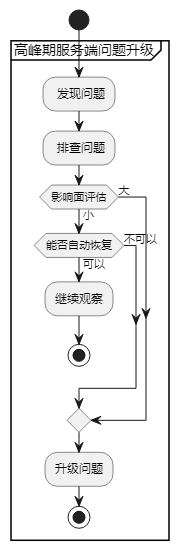
问题升级步骤
SRE人员-各端组长-业务线负责人
现有降级手段
App业务入口降级
降级范围以及作用域
使用App降级策略,App在各个业务入口会直接降级,关闭对应的业务入口
使用场景
- 对应业务出现会持续扩大损失并且短期无法修复的报错,比如应用持续出现异常,并且异常会导致越来越多的脏数据影响业务流程
- 应用无法正常提供服务,并且确认无法短期内恢复。
AHAS限流降级
降级范围以及作用域
通过AHAS的限流能力,对核心应用接入AHAS,具备对指定接口做限流降级的能力。
使用场景
- 特定业务出现过量的访问或请求,在扩容之前,先使用AHAS进行限流保证已有业务不被打挂。
- 服务端出现短期内无法恢复的基础设施异常,使用AHAS进行限流降级,保证友好的返回。
应急预案SOP
MySQL
目前C端现有资源
rds_***等
表变更
现象
阿里云DMS审核表变更
动作
通知大数据,同步表待大数据确认变更的内容对他们的影响后,再执行。
长事务慢会话告警
现象
云监控-数据库层群出现C端实例的慢会话或者长事务告警
动作
登录das查看对应数据库实例状况,分析具体原因
- 如果实例会话中有异常会话,联系DBA,backup,帮忙杀死异常的会话
- 如果请求分析中慢日志某系统出现大量慢sql,视慢sql增长量,对该系统进行扩容处理
MySQL连接获取慢
现象
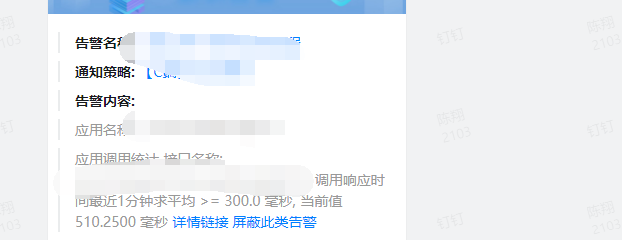
应用arms出现慢接口告警,并且链路追踪中耗时较长的步骤是druid或者hikari的getConnect等方法
动作
- 对应用进行扩容,按依次按顺序找SRE->组长->运维,其中的一个完成
- 观察慢接口数量是否下降,告警是否消失
- 调整应用数据库连接池配置,重新发布应用
Kafka
目前现有资源
kafka_**
kafka堆积
现象
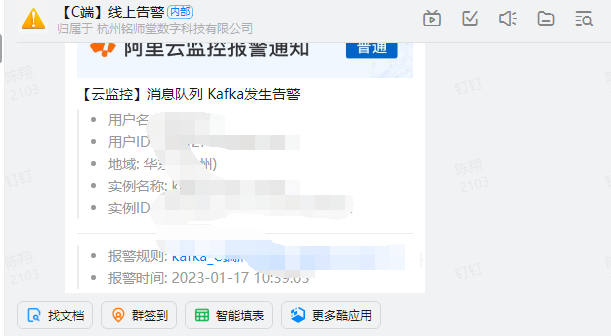
动作
-
登录阿里云kafka监控查看堆积的消费者组的情况

-
刷新查看堆积量的增长情况,如果堆积量逐渐减少,那么可能只是突增流量和业务导致的,可以继续观察,如果没有明显减少的情况,则对比分区以及机器数,如果分区>机器数,则扩容机器数到=分区数,如果分区<=机器数,则联系运维组扩分区+应用扩容,扩容后继续观察堆积情况。

## Redis
### 目前现有资源
redis_*
### Redis告警
#### 现象
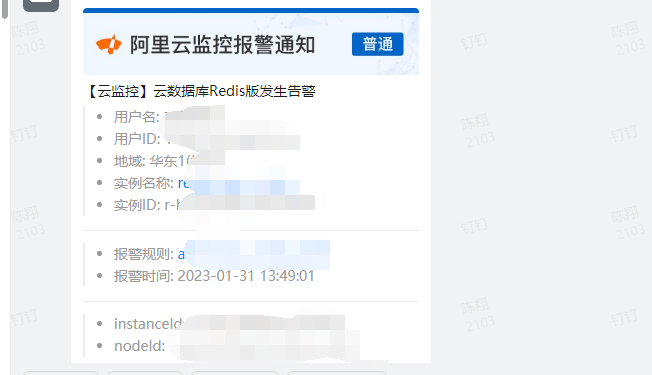
#### 动作
-
登录DAS查看情况,先看实时趋势,辨别一下是短期增长后回落还是还在持续增长。
-
-
主要查看内存和cpu使用率,一般是这两个告警
-
-
依靠实例会话里慢日志和缓存分析,查看导致异常的应用或者会话或者业务,如果对redis整体的影响增加很大,那么需要对对应的业务做降级,如果影响不大,那么则马上安排优化该业务
## 服务
### 目前C端现有资源
all
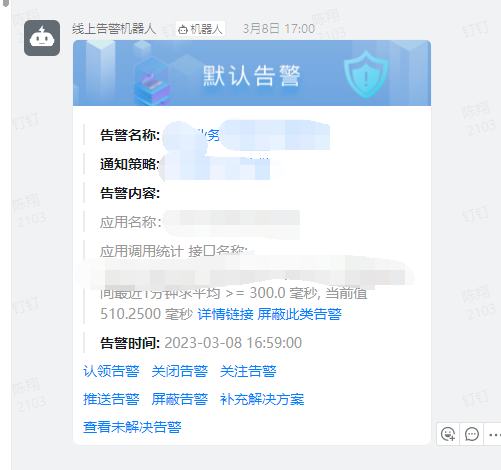
### 慢接口告警
#### 现象
#### 动作
-
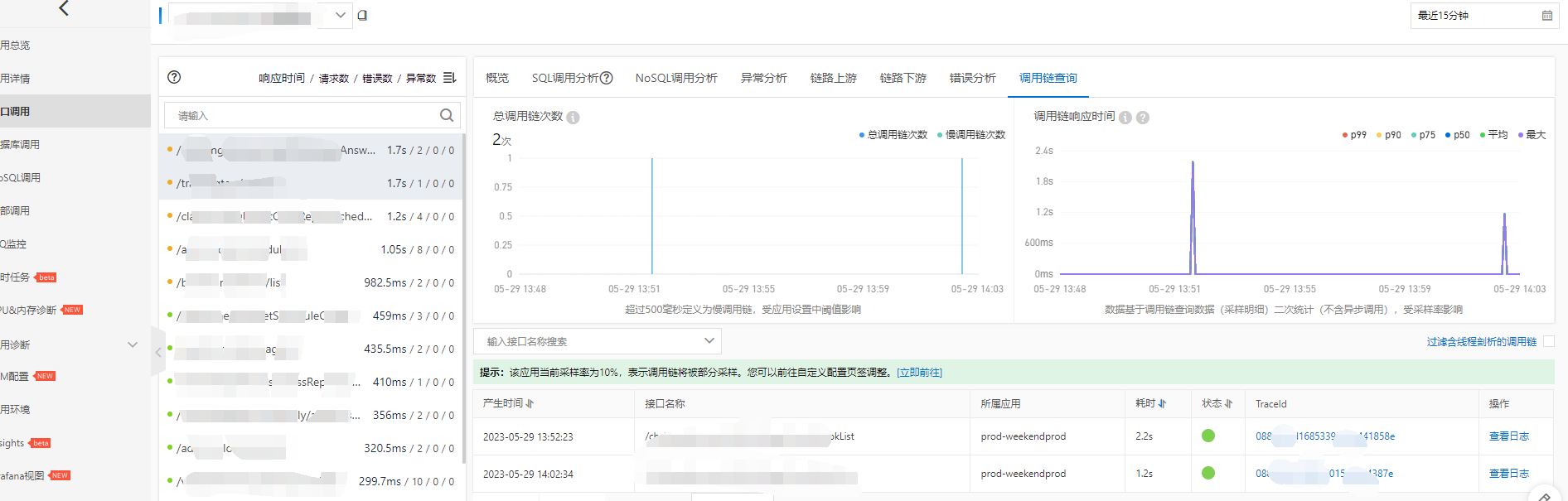
登录arms查看情况,对应应用-接口调用-调用链查询-按时间排序。
-
-
点击traceId进入排查接口慢的原因,如果是下游慢,联系下游排查处理,如果是中间件(mysql或者redis)慢,看一下是否某个sql导致的
-
观察慢接口出现的频率是否持续上升,如果没有缓解并且短时间内无法解决,马上使用ahas对该接口进行限流降级。
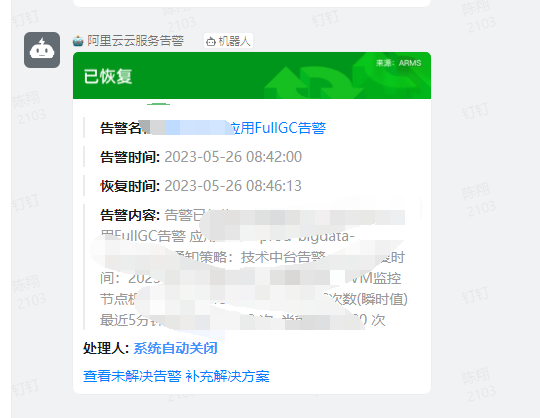
### Full gc告警
#### 现象
#### 动作
- 登录arms查看情况,对应应用-应用详情-JVM监控。
- 查看gc情况以及堆内存情况,如果只是单pod的fullgc次数越来越多但堆内的老年代内存没有明显回收释放,那么需要对有问题的pod进行手动重启。
- 如果只是比较稳定的进行full gc并且老年代回收较为理想,但应用扔保持触发告警阈值的频率,那么可能只是单纯量上来了,需要对集群进行扩容。
-
线程池告警
现象
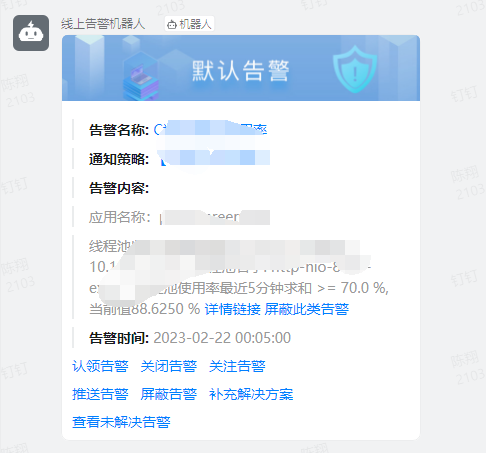
动作
-
登录arms查看情况,对应应用-应用详情-JVM监控。
-
-
查看JVM监控中的线程数,是否有明显的尖刺。
-
查看是单pod的问题,还是整个集群每个pod都有问题。
-
如果单pod的问题,重启该pod。
-
如果是整个集群的每个pod都有该情况,扩容集群,观察情况是否有缓解。
### 错误率告警
#### 现象
#### 动作
- 点击链接进入sls,查看对应服务的error日志
- 具体情况具体分析,如果对系统影响较小,或者可以业务上进行修复恢复,那么就业务修复处理。
- 如果对业务影响较大,并且会持续出现脏数据或者报错,那么对业务进行降级