这章主要介绍了空闲内存管理的一些内容,不过要先弄清楚前提,本章的内容是基于段来管理内存并且主要描述的是在管理段的内存时,内存分配库(malloc)或者os需要考虑的一些方面或者设计。有一点需要明确,否则很容易混淆:本章主要讨论的是内存分配库或者os管理某一个段内内存的情况。
内部碎片以及外部碎片
结合上一章,在段的前提下,内存的碎片进一步扩展,可能会有内部碎片以及外部碎片,外部碎片就是段之间在实际物理内存之间的碎片,主要是因为内存中分配了很多段,导致新的段无法分配所以需要压缩段之间的空间。
内部碎片就是某个段(本章以堆举例)之中,其中在内存不断进行回收以及分配的过程中,在单个段中产生的内部碎片。其实主要也就在堆中有了,因为代码段的内存和栈中的内存由编译器早早决定,其中的碎片比起由用户进程控制的堆来说可以说是小巫见大巫了。
不过其实对于内存管理来说,不论是管理段,还是管理段内的内存,无非要面对的对象也就是一段又一段各自内部连续内存,但彼此之间又分割开的内存子空间罢了,所以内外部碎片的管理思路大同小异
段(堆)如何变大?
段如果在内存管理库在使用时发现大小不足,会使用系统调用sbrk中断来交换到操作系统,由操作系统来在内存中重新换一个更大的连续空间来防止这个段,并且由OS来保障原有的数据copy到了新的内存段中
空余内存空间管理的底层机制
碎片的产生,或者说压缩的必要性
底层机制很简单,这里简单使用一个链表来描述整个过程。这本书对于描述过程和要讨论的机制,都使用最简单最容易理解的数据结构,以使得主要把注意力集中在要处理的问题以及OS的职责,而不是那些精妙的数据结构如何运作
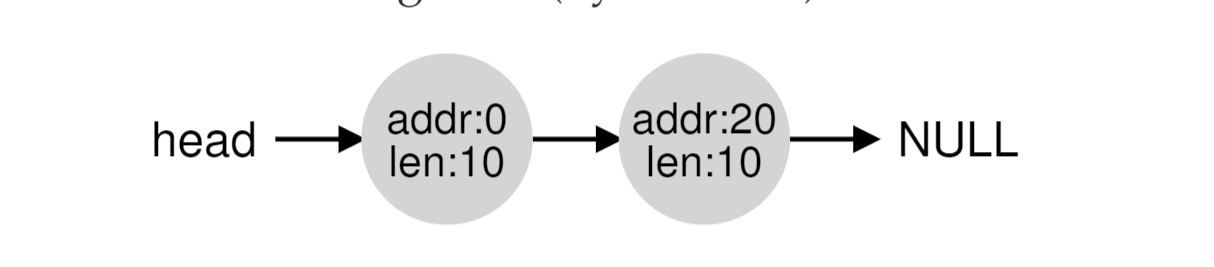
这里略过一些文中过于复杂的过程赘述,这部分对稍微有一些算法或者有一定编码经验的人来说很好理解。对于内存的管理,我们使用一个链表来维护其中空闲部分的状态。
以上图为例,链表中有2个节点,第一个节点表示地址0开始有一个长度为10的空闲内存,第二个节点表示地址20开始也有一个长度为10的空闲内存。可以很容易看出来,此时addr10,len10这部分空间是在被使用的。
如果addr10,len10被free了,那么整块内存就连续了。当然,第一步我们会把addr10,len10这个节点,加回链表中,此时链表有3个节点,也就形成了我们要讨论的碎片的一种形式,因为此时要申请一个30len的内存,按照3个节点来判断,我们在压缩前是无法申请的,所以我们就必须要将3个节点压缩成一个addr0,len30。
这部分应该很好理解
追踪已分配内存的大小
其实从上面那个列表已经可以看出来,每个节点需要一部分额外的空间作为header去描述这部分内存的大小,简单来说就是一个size和一个magic。其中size就描述了这段内存的大小。magic作为魔法值用于完整性的校验(大抵是供内存库来校验这部分是否是它自己分配的?说实话不太懂要来校验什么)。那么在使用free来释放内存时,我们自然可以通过传入的指针马上拿到这部分的大小,来快速完成内存的释放(把这部分内存加入回free list里)。当然,这也使用了额外的一丢丢内存来储存这个header,所以在实际搜索位置去分配的时候的时候,如果用户要求20byte,那你要搜索到实际空闲的22byte才可以完成这个内存分配。
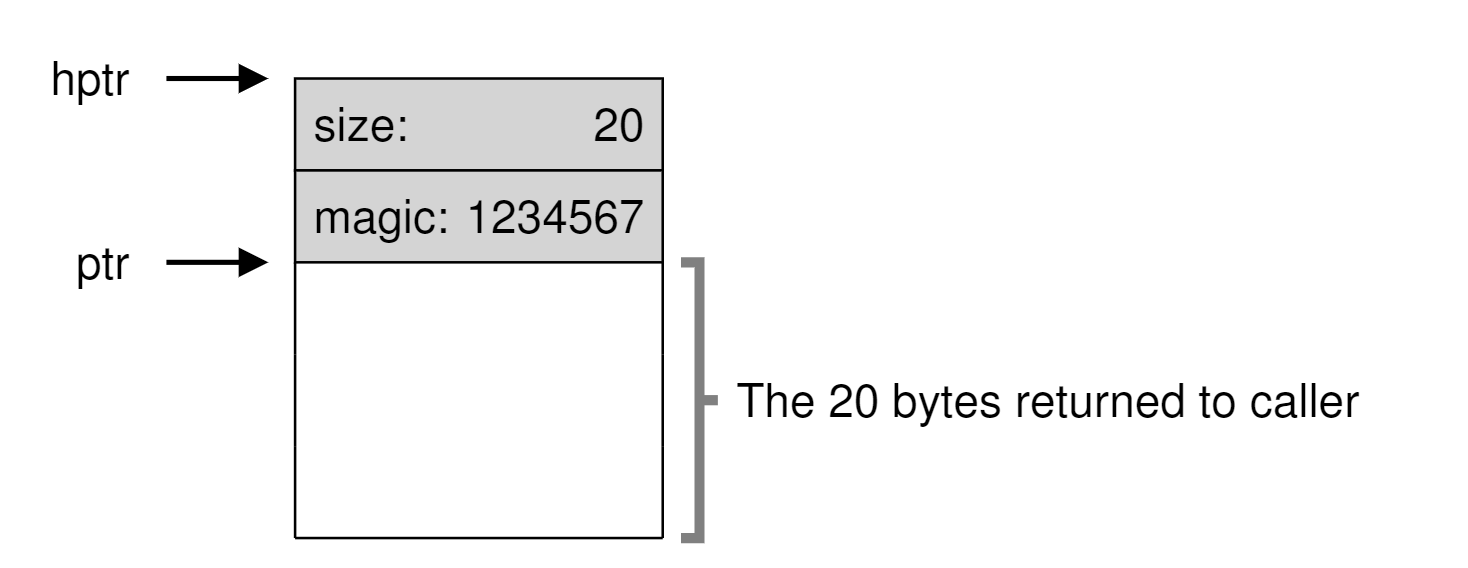
通过header、head指针、next指针,在储存空间本身中内嵌free list
这里是一个比较巧妙也比较复杂的设计,这章大多数内容和图都在描述这个设计。
为了避免free list本身使用额外空间储存,所以通过链表的设计,巧妙的把这个free list内嵌在空间本身中。这里精炼下这个过程。
首先,我们认为内存还没分配,这个时候head指针在一开始,我们认为整个free list只有一个节点。
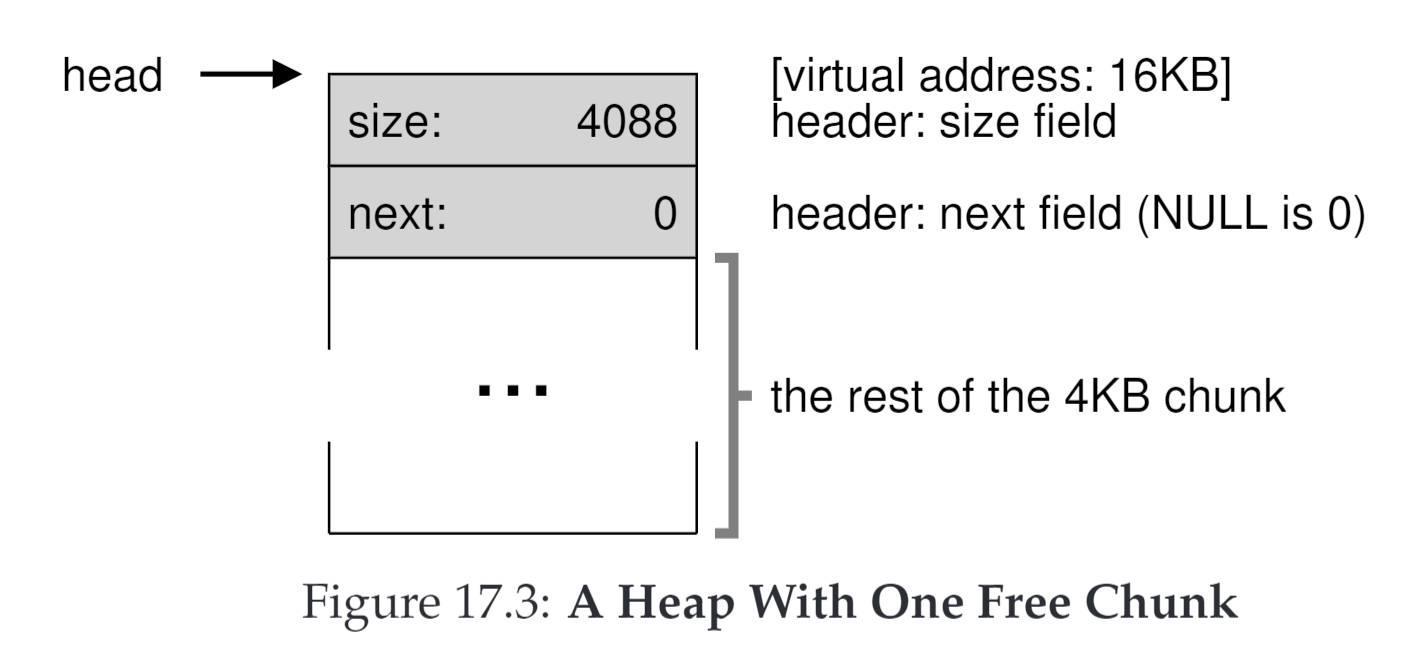
在经历一系列的分配以后,我们的内存变成了下图。这里的主要逻辑是:每次从head开始遍历,满足分配的话,就将那部分新增一个头,头中只有size和magic(注意此时没有next只有最后的节点才有next)。从下图可以看到,head还在最后,前面分配的空间都只有size和magic,下次分配时继续从head开始遍历到next=0(当然现在也就只需要遍历一个节点)。

然后释放free的时候,就比较巧妙,在某段释放以后,会通过从head开始遍历+修改某个节点的next指针的方式,将释放的那段内存加入到free list中去。原文中多了一个图,但是略微有点误导(其中包含了较为复杂的实际处理逻辑)。我们直接看下图,在释放了一系列开始申请的内存以后,现在的free list实际为(按照灰色区域的顺序,从1开始)head->3->1->2->4->null。
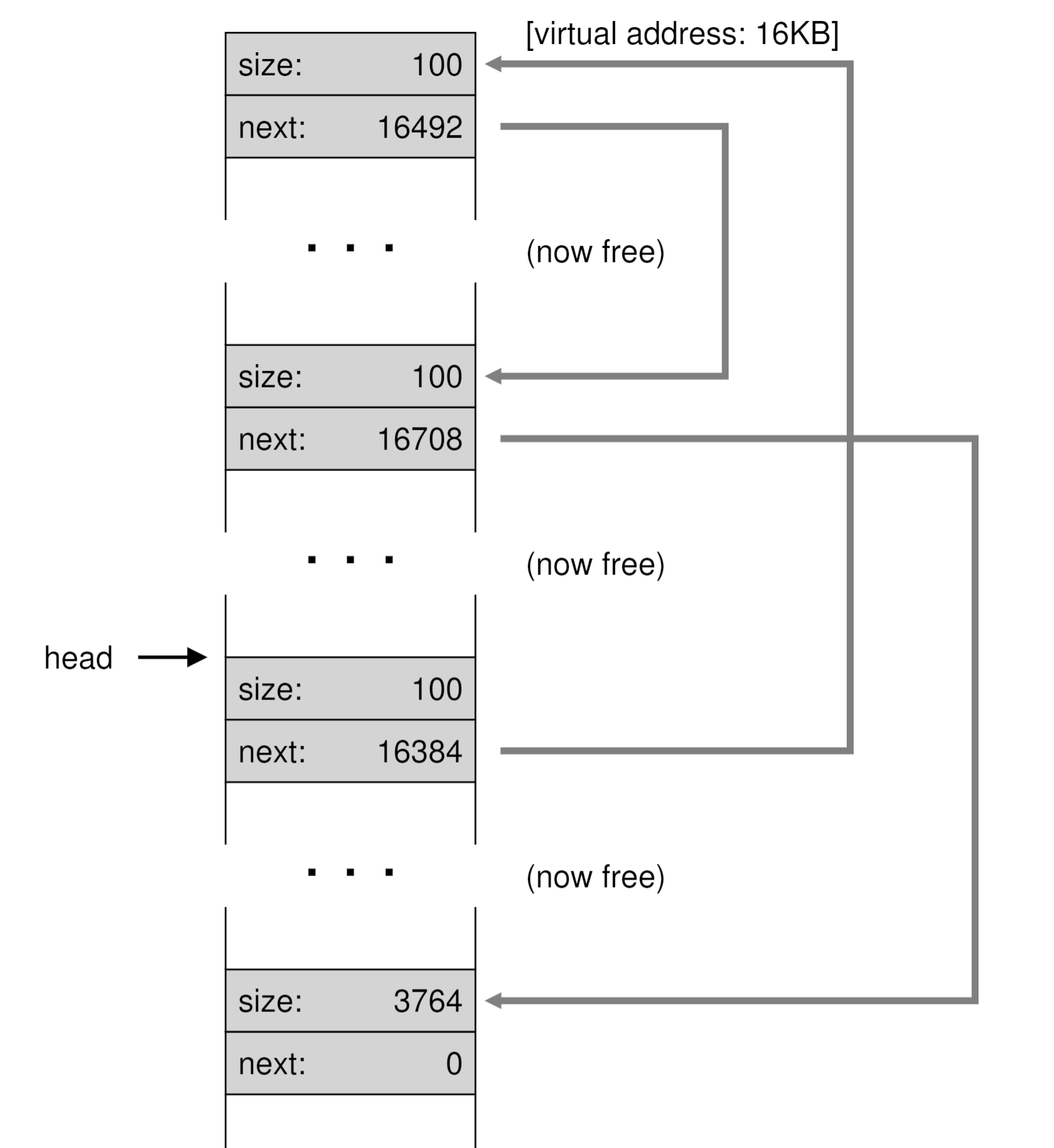
最后,在这种复杂度达到一定程度时(节点过多),我们就可能需要考虑触发下合并的逻辑了。当然,即使不合并,我们依旧可以通过head遍历到next=0,来完成这个free list的遍历。
这种设计很巧妙,只是多使用几个字节(next)的内存,就可以把free list嵌入内存中。
挑选节点的基本策略
每个空闲节点有大有小,遍历时挑选的一些常见基本策略,这里稍微列举下,很好理解
Best Fit最佳大小匹配
这个策略很简单,查找空间大于等于所需空间的最小节点。举例来说,如果我要分配5byte(带上header),现在空闲的有1,3,5,7,11,15。那么就会选到5byte那块去分配。
优点:减少浪费的空间以及意外的碎片,比如如果选择7的话,产生的2byte碎片大概率在压缩前会一直浪费掉
缺点:需要找到最佳匹配,需要遍历整个列表,并且因为需要记录状态(上一个最接近的)会产生额外的性能和空间损失。
Worst Fit最大匹配
与Best Fit相反,这个是遍历后找到最大的去分配
优点:产生的碎片很大
缺点:也需要遍历,而且据文中所说,大量研究表明这种方式会导致过度碎片化并且性能非常低
First Fit 首次匹配
顾名思义,找到的第一个可以分配的节点就直接分配。
优点:快,不需要遍历所有节点
缺点:可能会被大量小块占据了头部导致遍历变慢。但是可以通过地址的顺序来进行合并,这样合并很快可以一定程度上解决这个问题。
Next Fit 匹配
这个算法并不总是在列表的开头开始首次适应搜索,而是保留一个额外的指针,指向列表中最后一次查找的位置。这个想法是在整个列表中更均匀地分布对自由空间的搜索,从而避免列表开头的分裂。这种方法的性能与首次匹配非常相似,因为再次避免了穷举搜索。
其他种类的内存管理方式
隔离列表
这个其实不太理解为什么叫隔离列表。但是思路比较简单,其实是一种异种的列表。这个列表专门管理那些常用的、固定的内存对象分配(文中举例是锁、文件系统的node)。比较定制化
优点的话举个例子,如果某个场景大量重复申请释放4byte的空间,那么我专门设计一个逻辑去具体处理4byte内存的申请释放。每次只允许4byte,需要考虑的场景就少很多,性能大大提升。
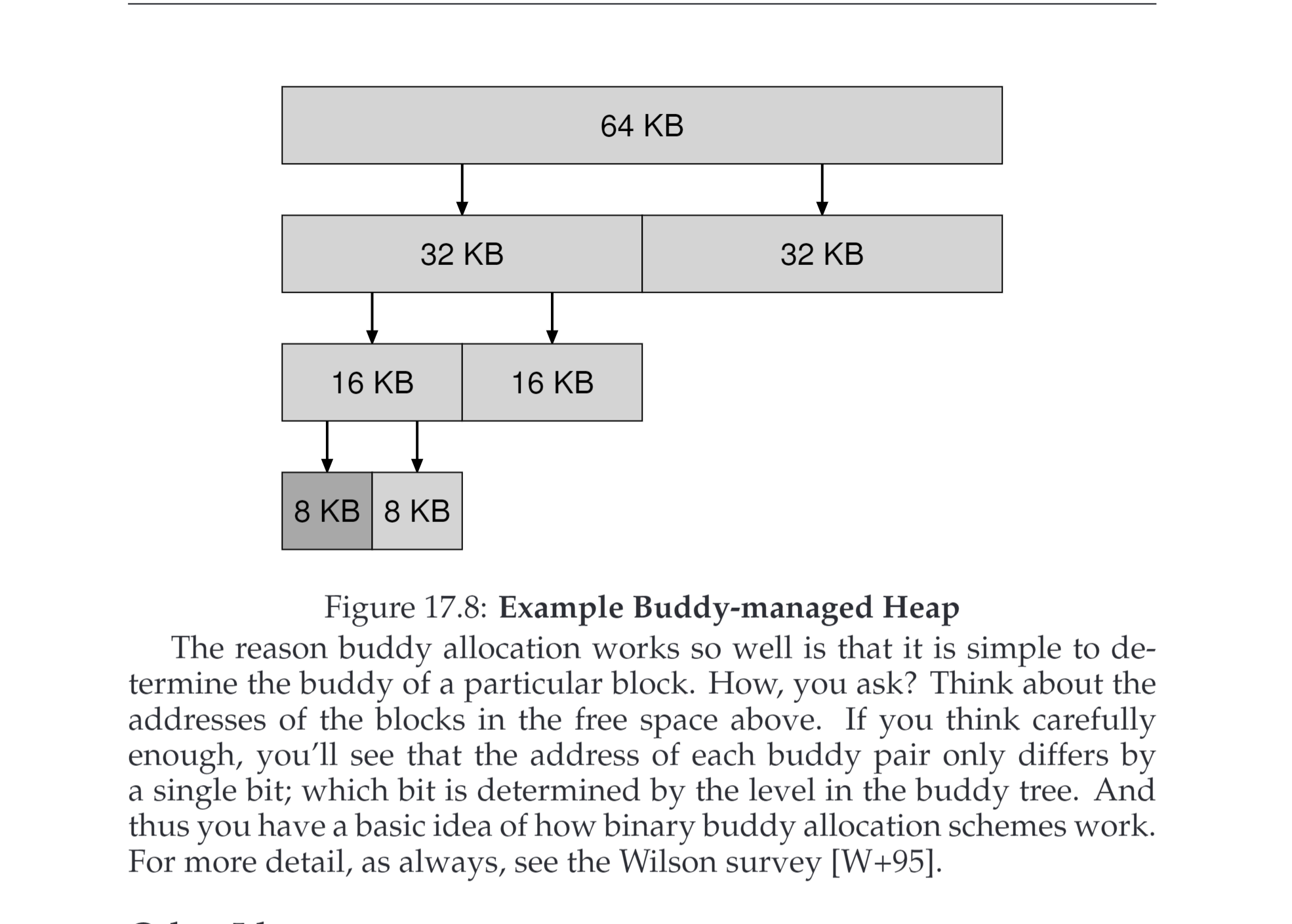
Buddy Allocation兄弟分配
这个一图就可以说明,利用二进制块,进行分配以及回收,优点就是压缩非常快(基本不需要压缩),缺点就是不够灵活并且有一定空间的浪费
总结
空闲内存管理本身就是一种权衡,来挑选使用什么数据结构或者方式去维护空闲的列表。权衡需要兼顾到额外空间的使用、空闲空间搜索的效率、压缩性能的考量。
真想要了解到最核心的知识以及实现,去看glibc的内存分配就完事喽。