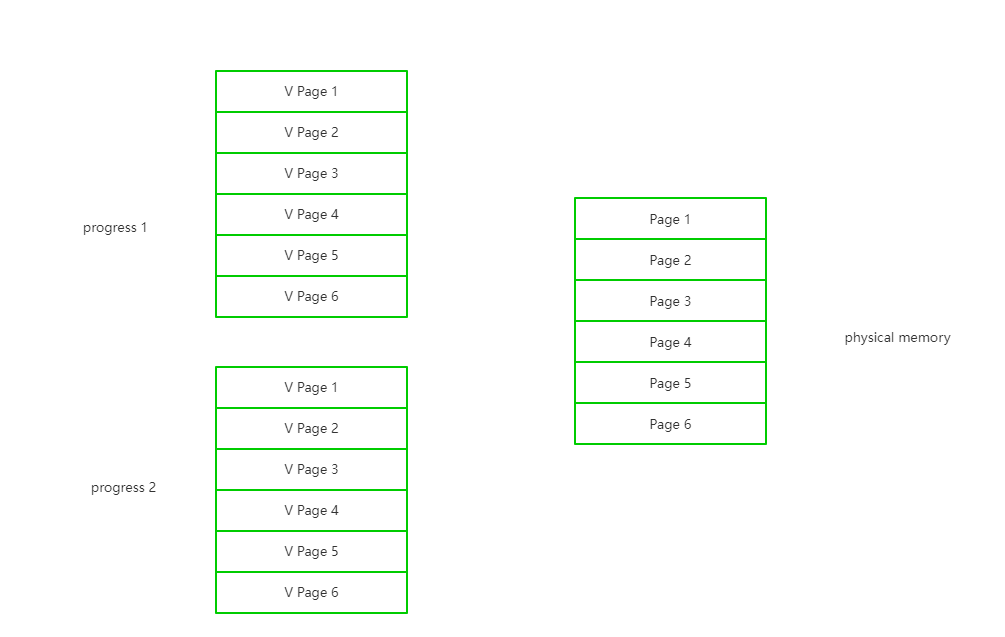
本章主要讨论如何加速页码的转换,即如何快速通过虚拟页码找到物理页
TLB的概念
TLB(translation-lookaside buffer)是处理器芯片上内存管理单元memory-management unit的一部分,本质上是一个对于最近转换关系的一个高速缓存,所以从功能来看其实更贴切的名字是address-translation cache,叫TLB是因为历史原因。
通过缓存来加速这个步骤主要是考虑到了时间局部性和空间局部性。
这在我们前面了解CPU高速缓存的时候提到过。比如18章中那个循环1000次每次+1的值,在内存中需要访问的数组可能都在连续的页上,这更符合空间局部性(访问某元素后,马上要访问下一个紧挨着的内存,不过在这里是页)。用于统计的sum和循环计数用的i,在循环执行时会被多次访问,这符合了时间局部性(被访问过的内存、页,在接下来短时间内可能会继续被访问多次)。
TLB元素的结构
TLB元素的结构很简单,VPN | PFN | other bits
另外的那些bit位,就用于保存一些标记位
实际的一个实例:

TLB缓存缺失的处理
CPU高速缓存缺失数据时,由CPU从内存中读取到数据并缓存。那如果在TLB中缺失某页的映射信息,那么该交由谁处理?
CPU的指令集有复杂指令集CISC和简洁指令集RISC。古早的硬件设计者们不太信任OS的开发者,所以他们使用CISC复杂的指令集来让CPU自己去处理。而RISC则是在发现缺失缓存后,由硬件触发一个中断,将事情告知OS,然后由OS自己来去处理这个问题。
由OS处理就会和处理一般中断有一些比较大的区别,比如在某行代码触发一般中断后,实际上就该执行下一行代码了。而由TLB触发的缺失中断,在OS将缺失映射关系写会TLB后(要知道TLB在芯片上),需要再次执行一次触发中断的代码,此时这行代码就可以从TLB中读到数据了。
不过这件事情也没有那么简单,因为如果OS处理完后,TLB出于某种淘汰策略把刚写进去的数据再次淘汰了,那岂不是可能无限循环了?所以OS处理这个问题是要考虑的问题实际要更多。
另外就是,OS也会将一些OS自己的内存页等,永久保持一直在TLB中而不被淘汰,以提升OS自己的性能,这也是OS需要考虑的问题。
TLB与进程切换的难题
因为TLB在芯片上,并且缓存的是某个具体进程的虚拟页转换关系,那么在线程切换时,就会遇到CPU缓存一样的问题。
不过因为现在TLB的写入以及控制,我们交给了OS,所以这个问题通过OS在CPU切换进程的时候,将这个进程的TLB内容保存到进程信息里,在切换回来时flush回去,我们是可以解决的。只是这需要成本,并且这个成本很大。
另一种处理方式是由硬件TLB提供兼容,TLB在存储的时候除了存储虚拟和物理页码之外,另外存储一个id,这里可以是进程id的某种表示,这样对于TLB内的数据,就有了一个字段去区分进程间的数据,这样就不需要flush了。不过这未尝没有代价:TLB的命中率会受到影响。
TLB淘汰策略
TLB中的数据的淘汰策略可以有很多,随机、LRU,但是这个是我们需要考虑的